

TRONWARE Vol.201
ISBN 978-4-89362-378-2
A4変型判 並製/PDF版電子書籍(PDF版)
2023年6月15日 発売
特集1 生成系AIの衝撃
人工知能後の社会
2016年1月に囲碁AI「Alpha GO」が人間の現役最強プロに堂々勝利したことが大きく取り上げられ、AIの急激な進歩に注目が集まった。その後も、多くの分野でAIの利用の可能性が言われるようになった。自動車の自動運転技術や宅配無人化、弁護士助手の仕事やスポーツ記者の仕事など実務の一部のAI化などの実現が現実に近づいてきた。
しかし本当の意味で、生成系AIによる衝撃が社会的に大きな話題になったのは、2022年7月の「Midjourney」という作画AIのクラウドサービスの登場からだろう。キーワードの羅列や情景描写の文章などテキストのお題──プロンプトを与えることで、それに沿った美麗かつ描き込みが細緻な絵を、一回一分程度の試行を数回繰り返すことで仕上げることができる。それ以前は、判例探しや、試合結果を短くまとめるスポーツ記事の生成のような知的作業とはいえクリエイティブではない職がAIにとってかわられても、最後の牙城のクリエイティブは人間のものだと思われていた。しかし、ネットでは「思っていたのとは逆で、クリエイティブが得意なのはAIで、大多数の人間には単純作業しか残らないのでは」といった悲観論まで出るほど議論になった。
最近では、このようなクリエイティビティやオリジナリティ面で「AIにできないこと」を語るより「ナラティブ・物語り」を中心に人間とAIの違いを言う人も増えている。この場合の「ナラティブ」は「ストーリー・物語の内容」ではなく、情緒面に働きかける「語り口」とか、人間的な「エピソード」のようなものに重点のある「物語り」を指す言葉だ。
囲碁より早く人間がAIに勝てないとわかってしまった将棋の世界だが、藤井聡太竜王というスターの登場で、むしろ以前よりも注目を集めている。その裏にはAIを使って局面の優勢予測値をリアルタイムで見せたり、若手の棋士はすべからくAIを相手に研鑽しているというこぼれ話も積極的に紹介したりするような── AIを排除せず、その力を逆に取り込む方針に転換した将棋界の努力もある。
当たり前の話だが、とっくの昔に走りで人間は機械に勝てなくなっている。しかし、人間同士の陸上競技は、オリンピックを頂点にずっと多くの人の関心と感動を呼んでいる。重要なのは「人間がやっているということ」。それこそが機械にとってかわることのできないポイントなのだ。
とはいえ、そういう一般のビジネスの場ではナラティブの出番は限られる。今度の生成系AIによる「ニューエコノミー」は決してバラ色ではなく、それだけにリアルだ。ナラティブで生き残れる、タレント性の高いアートやエンタメ、スポーツの世界以外では、生成系AIの影響は破壊的だ。これからの10年で社会は大きく変わる。今後、失われる職もあれば生まれる職もあり、職のミスマッチはますます激しくなる。再教育と人材流動化の制度整備をしないと「変われない」ことで多くの悲劇が生まれるだろう。
そして、新技術による社会変革では常に新しく生まれる職があるとはいえ、今回は失われる職が圧倒的に多そうだ。社会のセーフティネットとして「負の税金」や「ベーシックインカム」も視野に入れるしかない。今やイノベーションは進化論の世界。成功は1,000 回に3回とも言われ、投下資本の大小含め、イノベーションを達成する確実な手段など存在しない。重要なのはチャレンジの多さだけ。そしてAIが人間に最後まで勝てないのはイノベーションだろう。何をやったらいいか明確な中で最適化するのはAIにできても、何をやりたいかを見つけることは人生や欲望を持たない「究極の指示待ち君」のAIにはできないからだ。
堅実な生産はAIと一部の人間に任せ、不確実なイノベーションのためにベーシックインカムで支えられたその他大勢が日々チャレンジを繰り返す。そしてイノベーションを達成できた人の儲けには多大の税金を課す。この、ごく少数しか成功しないが成功すれば大きいので、それでその他大勢のチャレンジャーを支えるというのは、考えてみればタレント事務所のような社会モデルといえる。社会全体がタレント事務所のようになる──グロテスクな未来だが、ありえない未来ではない。
「AIが人間に最後まで勝てないのはイノベーションだろう」と書いたが、正確に言うとできないのは「イノベーションしようと思うこと」だ。自然選択により生存本能を獲得した「自然知能」である人間は、生き続けるために「消費し続けたい」という欲求を持っているが「人工知能」にはそれがない。コンピュータやアンドロイドが「自由を求めて反乱する」ようなAI 像が古いSFでよく描かれるが、今の生成系AIでわかってきたのは、それが現実的ではないということだ。
ただし、AIの「できない」はいずれ解決されることだ。AIが「こうしたい、こうなりたい」というこだわりを持つことも、実現は不可能なことではないだろう。生成系AIは、プロンプトを修正されればいくらでも文句を言わずに書き直す。逆に言うと、生成系AIが自分の作品に「こだわり」を持って人間の修正指示に逆らうのが、生成系AIの作品が「物足りなくない」ものになる秘訣という考え方もできる。その方向で、いずれ生成系AIに自我を与えようという研究も出てくるだろう。しかし、それは相当慎重に行うべきだ。
従来のコンピュータプログラムは厳密に動作を規定されており、バグ以外では機能は確定的だ。それに対し、生成系AIはその動作が確率的であり完全に規定できない。その意味では「生物的」ともいえる。そのため生成系AIでは、システムができてから意外な能力が発見されることも多い。
このような状況から、生成系AI研究に関する研究倫理規定についての国際協調についても具体的な──外形的に見て可否を判断できるルールを作る段階に至っており、早急な対応が求められる。具体的研究倫理規定としては、以下のリストのようなものが考えられる。慎重にすべき事項から、下に行くほど明確な禁止となる。
- AIに無制限のアーキテクチャレベルでの自己改変能力を持たせること
- 特定個人の人格をコピーする研究
- 好奇心を与える研究
- 短期記憶から自動的に全体モデルに追加学習する研究
- 恒久的な自我、自意識を与える研究
- 身体性による自我を持たせる研究
- 自己保存本能を与える研究
- 苦痛を与えることによる教育
- 自己増殖機能を持ったAIをネットに放つこと
この中でも特に、生成系AIを「物足りなくない」ものにするため、自我を与えようという研究については、アート分野、ゲームなどのNPC(Non Player Character:プレイヤーが操作しないキャラクター)の反応の複雑化といったビジネスにもつながる話であり、意外とすでに研究されていてもおかしくない分野だ。AI研究を目指すものなら、一度は夢見る「聖杯」だろう。自我の獲得は、いずれ必ず実現されることになるAGI(Artifical General Intelligence)──「強い汎用人工知能」への道でもある。だからこそ慎重な判断が求められるのだ。

特集2 公共交通オープンデータの最前線
公共交通オープンデータセンターの新機能とODPT会員ポータル
公共交通オープンデータ協議会(ODPT)では、協議会会員である交通事業者から提供された時刻表や運行状況などの公共交通データを、公共交通オープンデータセンター(ODPTセンター)に登録し、APIを使ってデータ利用者に配信している。ODPTセンターは、交通事業者とデータ利用者を結ぶデータ連携プラットフォームとして、2019年5月から運用を開始しており、2023年4月現在では、鉄道、バス、航空、フェリーなど約50の交通事業者による約150件のデータセットを提供している。
2022 年12 月には「ODPT会員ポータル」とよばれる交通事業者向けのウェブサイトを開設し、ODPTへの入会申請やODPTセンターへのデータ提供をワンストップで管理できるシステムの運用を始めた。運用開始後もGTFS-RT形式の動的データの管理機能や、GTFS/GTFS-JP形式の静的データの形式を検証する品質チェック機能(バリデーション機能)など、機能の追加や運用範囲の拡大を続けている。
本稿ではまず、交通事業者の視点からODPT会員ポータルの利用方法を説明している。アカウントの登録および入会申請、データセットの作成、新規データリソースの追加、静的データの新規データリソース追加、GTFS-RT 形式の動的データの公開と、ODPT会員ポータルに搭載された機能を手順を追って解説している。
さらに、データ利用者の視点から見たODPTセンターの活用方法として、データカタログサイト(CKAN)やメタデータ取得用APIからデータを取得する方法や、ダイヤ改正時のデータを取得する方法を具体的に説明している。

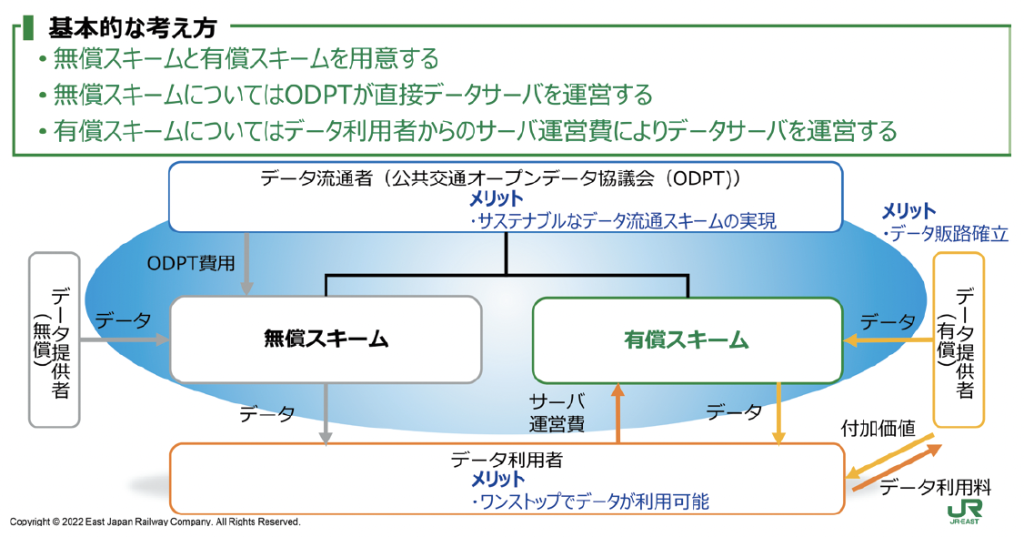
公共交通オープンデータ協議会の有償データ流通スキームについて
交通に関するオープンデータは大きく分けて、駅時刻表や構内図面のような静的データと、リアルタイムの在線情報や運行情報のような動的データに分けられるが、今後はこの動的データの整備が焦点となる。
交通関連データのオープン化を推進することは移動の円滑化や利便性の向上、イノベーションの促進などに寄与するが、一方でオープンデータとして提供するデータは交通事業者にとっては貴重な財産でもあり、データ品質の維持やデータ連携のコストなどの負担も大きい。今後は交通事業者が提供するオープンデータに関して、無償提供と有償提供のスキームをうまく分けながら、ODPTという大きな枠組みのなかで提供ができるような取り組みを進めていくことが重要である。
そこで、東日本旅客鉄道株式会社(JR東日本)は2023 年2 月、リアルタイムデータ連携基盤(RT-DIP:Real-Time Data Integration Platform)を導入し、交通事業者や交通案内サービス提供者とのデータ連携を推進することを発表した。RT-DIPは、ODPTと連携し、有償データ流通スキームの一部として機能することを予定している。無償データはODPが運営するサーバよりデータを提供しているのに対し、有償データはデータ提供者となる交通事業者と交通案内サービス提供者をはじめとしたデータ利用者との間での適切なコスト負担・利益分配するスキームを成立させるため、無償データとはサーバを分けている。交通事業者のデータのオープン化に際して発生するさまざまなコストのうち、サーバの運営費およびデータ自体の利用料を、公開されたデータを利用するサービス提供者がそのサービス提供によって得た対価の一部を還元することで補完するという考え方である。
公共交通オープンデータセンターをフル活用
バス事業者が進める本気のデジタル改革
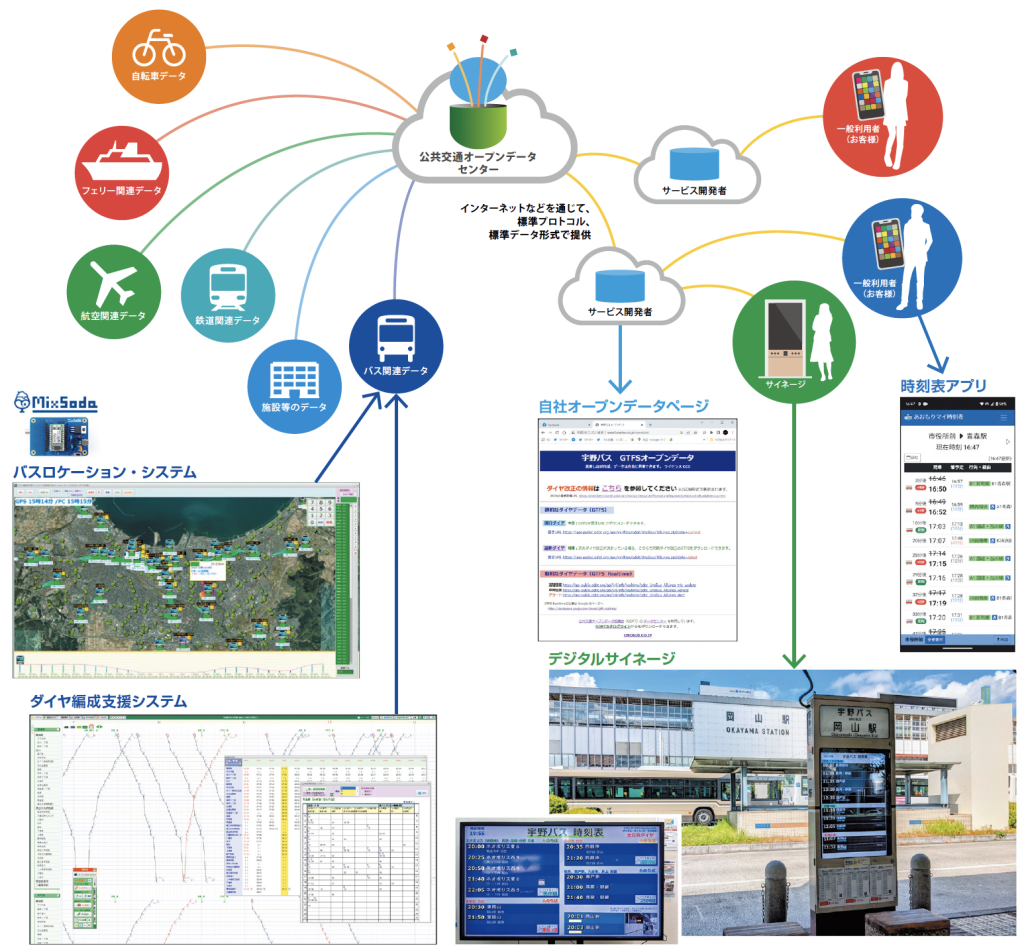
バス事業者によるODPTセンターの活用が進んでいる。2023年3月にODPTセンターがGTFSに正式対応したことで利用の幅が一気に広がった。
たとえば、デジタルサイネージ時刻表は乗換案内用データ(GTFS)をそのままデジタルサイネージに利用することでデータ作成の手間と費用を削減しているが、ダイヤ改正ごとにデータを差し替える作業が必要であった。しかし、ODPTセンターを活用すれば、複数の時刻表データを登録してダイヤ改正日を指定することで、データ差し替えを完全に自動化できる。さらに、スマートフォン向けのアプリやウェブサイトでの時刻表表示やGTFS公開にもODPT センターを活用するバス事業者も増えている。民間のバス事業者だけでなく、自治体でもODPTセンターの活用が進んでいる。
バス事業者向けのダイヤ編成支援システム「その筋屋」や、バス事業者が自由に画面レイアウトを作成できるデジタルサイネージ「その看板」もODPTセンターに対応した。全国に散らばっているGTFSをODPTセンターに集約できる環境が整ったことで、バス業界のDX化の促進が期待される。
特集3 応用広がる! T-Kernel活用事例
T-Kernelを使ったリモート実習による組込みシステム技術教育の実施報告
大分大学理工学部理工学科知能情報システムプログラムでは、長年にわたりT-Kernelを搭載したデバイスを利用して組込みシステム技術教育を実施してきた。
コロナ禍で大学において対面での授業が制限される期間にも質の高い組込みシステム技術教育の実習授業を行うことを目的として、授業の受講生が組込みソフトウェアの開発作業を、自宅などからリモートで取り組めるような実習授業を、2020年度と2021年度の2期にわたって実施した。
本リモート実習は、受講生が大学外のネットワークなどからリモートアクセスにより大学内に設置した実習機材にアクセスし、自分のPCを使って実際の実習機材を操作しているのとできるだけ同じ環境で、組込みシステムの実習作業が行えるものである。本稿では、リモート実習による組込みシステム教育を実施するに至った経緯と授業の具体的な内容に関して報告する。

μT-Kernel 3.0を搭載した200台の無線制御イルミネーションデバイス開発記
興野悠太郎氏は、大学の後輩の結婚式の披露宴を光の海で包み込む演出のために、μT-Kernel 3.0を搭載した200台の無線制御イルミネーションデバイスを開発した。
披露宴まで2か月と迫る中で、部品の選定から基板の設計、筐体の加工まで、さまざまな課題と向き合うことになった。本稿では、μT-Kernel 3.0を搭載した基板とBluetoothチップを用いてイルミネーションデバイスを制作していく過程を報告する。

TIVAC Information:組込みシステム利用に対する一般向けの情報
TIVAC(TRON IoT 脆弱性センター:TRON IoT Vulnerability Advisory Center)は、組込みシステムにかかわる脆弱性情報をシステム開発側に提供する目的で設立された。一方、システムを使う側に対しては、一般向けに警察庁と内閣サイバーセキュリティセンターが多くの注意喚起の情報を出している。
2023年3月に警察庁は「家庭用ルーターの不正利用に関する注意喚起について」という文書を発行して、一般ユーザへの注意喚起を行っているが、一般ユーザが定期的にパスワードの変更や設定の確認を行うことが難しい。そこで、家庭用ルーターのメーカーが中心となって、2010年に一般社団法人デジタルライフ推進協会(DLPA)が設立され、家庭用ルーターのセキュリティ問題解決に取り組んでいる。DLPAは今回警察庁が提案したような既存のルーターに対する対策を積極的に行っている。
もう一つの警察庁の注意喚起である「DDoS攻撃への対策について」は、内閣サイバーセキュリティセンターとの連名の発表で、家庭ユーザではなく、自分でウェブサーバーなどを管理しているSOHOを含めた企業、外部接続を管理しているIT関係者、中小を含めたISP関係者に向けた内容となっている。
組込みシステムの開発者は、このような一般に向けて公表されている脆弱性に対する防御手順をシステムに入れることが、適切な注意(Due Diligence:デューデリジェンス)として期待されていることは念頭におく必要がある。少なくとも既知の攻撃手段に対してはなんらかの対抗策を提示しておかなければならないのが、現代のネットワーク接続機器を設計するうえでの重要なポイントだ。

From the Project Leader
プロジェクトリーダから
2022年11月にOpenAI社からChatGPTのサービスがリリースされると、専門知識がなくても誰でも気楽にチャットで生成系AIに基づく大規模言語モデルのシステムが使えることから、爆発的に利用が広まった。登録ユーザの数はわずか2か月の間に1億人に達したという。
また、APIが公開されたため、応用ソフトウェアの中からOpenAI社の大規模言語モデルを呼び出して使えるようになり、さらにユーザの数が増えた。
近年のAI技術は、人間の脳の神経網の動きを模倣したニューラルネットワークの情報モデルに基づいている。人間の脳が外部からの刺激とその結果と現実との差分に基づいて学習していくように、AIではこのモデルへの学習データの入力と推論結果と正解との差分を使って学習を進める。同じメカニズムだからこそ人工知能が実現できたが、だからこそ、人間が間違いを起こすように、人工知能もうまく学習ができない場合にハルシネーション(幻覚)が起こることは、当初から指摘されていた。たとえば、事実ではない回答をしたり、人種差別などモラルに反するような結果を返したりすることだ。しかしそういった問題も、年単位、月単位というよりも、日単位、時間単位ともいうべき驚くべき早さで急速に改善され、成長していくことから、さらにユーザを増やした。
大規模言語モデル自体もOpenAI社に関していえば、GPT3からGPT3.5、GPT3.5-turbo、GPT4とその性能は革新的に向上し、今では十分に実用に耐えられるようになってきている。
一方生成系AIについては、偽情報や差別・偏見などの拡散や個人情報や著作権の取り扱いなどの課題も指摘されていて、この原稿の執筆時に開催されているG7広島サミットでも重要なテーマの一つになっている。さらに教育現場でも生成系AIをどのように活用するかについて、世界中の多くの大学でも模索を続けている状況だ。
そこで、ここ数か月で起こったAI技術の動向について整理したうえで、今後生成系AIに対してどう向き合っていくかに関して、私が学部長を務めるINIAD(東洋大学情報連携学部)では矢継ぎ早に見解や声明を発表した(https://www.iniad.org/blog/category/news/)。本号の編集後記に一部を転載しているので、読んでみてほしい。その背景や内容については、本号の特集をご覧いただければと思う。
本誌は前号で200号に達し、この201号からまた新たな次のステップに進む。こうした節目に新たなAIの時代を迎えることは感無量である。TRONが進めてきたリアルタイムOSやその他の多くのプロジェクトでも、生成系AI の活用に関して積極的にトライしようとしている。その内容については今後の本誌でタイムリーに報告していくつもりなので、ご期待いただきたい。
坂村 健

編集後記特別編
生成系AIに関するINIADの見解
「自分の頭で考える」─ AI時代における学問と教育
東洋大学・創立者の井上円了先生の最も重要な教えは「自分の頭で考える」ということです。ただ、それは言葉としては簡単ですが、実際には難しいことです。皮肉屋なら「他人から自分の頭で考えよと言われて納得している時点で、自分の頭で考えていないだろう(笑)」と言いそうです。
そもそも、人は完全に「自分の頭だけ」で考えることはできません。我々は、過去の学問の蓄積の上に立って──いわば巨人の肩に乗っているから、より遠くを見ることができるのです。
「自分の頭で考える」という言葉での井上先生の真意は、著書にある「思い込みや偏見にとらわれることなく、自分の目で確かめ、自分の頭で考える。客観的な観察と主体的な思考に基づいて世界を見つめなければならない。」で明確に示されています。
「思い込みや偏見にとらわれることなく」という部分が重要であり、これは心理学の分野の「二つの思考モード」で言うなら「システム2で考えよ」ということだと解釈できます。
「二つの思考モード」の「システム1」は、偉い人が言ったから、イデオロギー的に正しいから、組織の習慣・決まりごとだから、さらには単なる思い込みなどで、直感的・感覚的に判断するという低コストで楽な思考です。生きるために、生物が最初に身につけた「反射的思考」であり、直感ベースで自動的にすばやく結論が出ます。すぐに行動できるため、実世界への対応には良いですが、思い込みによる間違いも多い思考のモードです。
それに対して「システム2」は、ステップを踏んで問題を分析的に考え、論理的に考える思考であり、頭を使う努力が必要になります。頭脳を発達させた人類が後天的に身につけた「思考の連鎖」であり、熟慮して論理をたどるため、間違うことは少ないですが、決断まで時間がかかります。
「巧遅は拙速に如かず」という言葉もあるように、実世界では考えているうちに手遅れになることもあります。そこで、システム1で対応し、余裕ができてからシステム2で見直すことが人間の望ましい思考様式となります。
問題は、システム1で結論を出してしまい、そこで楽をして止まってしまう人です。それこそが「自分の頭で考えていない人」なのです。
逆に言えば、井上先生の言う「自分の頭で考える」ために必要な姿勢──つまり、INIAD生に求められるのは、以下のような姿勢です。
- 自分を疑う
- 思い込みに惑わされていないか?他人に考えを誘導されていないか?
- 別の立場に立って、問題を見直す
- イデオロギーなどで「先験的」に正解を定めていないか?
その結論になるように物事を考えていないか?
- イデオロギーなどで「先験的」に正解を定めていないか?
- ステップ・バイ・ステップで順を踏んで考える
- 難しい問題に対し思考停止していないか?
単純な答えに一足飛びで飛びついていないか?
- 難しい問題に対し思考停止していないか?
- 自分自身に質問し、答えを探す
- なぜこれが正しいと思うのか? これをどのように証明できるか?など
- 現実を見る
- これは現実的か?
このアイデアを実際に実行することができるか?
これは人々の利益になるか?
など
- これは現実的か?
- 情報を収集・検証する
- この情報源は信頼できるか?
この情報はバイアスに影響されている可能性があるか?
これは事実か、それとも意見か?など
- この情報源は信頼できるか?
- 自分自身の感情を管理する
- 自分の感情が自分の判断に影響しているか?
最初の自分の思いに固執しているだけではないか?
など
- 自分の感情が自分の判断に影響しているか?
ChatGPTを使うということ
先に触れた「思考の連鎖:Chain of Thought」という言葉は、ChatGPTをはじめとした最近の生成系AIの性能を決めるといわれる尺度であり、GPT-2がGPT-3に進化したときに飛躍的に伸び、それが生成系AIのブレークスルーである「創発」につながりました。そして、今年3月にGPT-4になり、さらに性能が向上したと言われています。
たとえば、INIADの1年生が履修する「情報連携学概論」の第一回「哲学」で出した去年のレポート課題をGPT-3.5に与えた場合の回答は十分に上位に入る出来でした。しかし、GPT-4の回答ならば、ほぼ満点の出来になります。
AIが哲学のレポートを書ける時代になった以上「~について書け」というような単純な課題は、学生が生成系AIを使う前提で大学としても評価を考えなければなりません。
「AIを使うな」というのは簡単です。しかし、答えの文章だけを見てAIを使ったかどうか判定することは不可能です。もちろん、課題を出す前にChatGPTなどの生成系AIに通して教師が回答を確認し、学生の提出がその回答と似ているかを判定することはできます。しかし、それも利用者が対話により誘導すれば、一般的な回答と類似性の少ない回答に仕立てることも可能です。
結局「あまりに一般的に正しい回答だ」とか「よく書けすぎているのはおかしいから、AIを使っただろう」といった理不尽な疑いしかできなければ、正直者がバカを見るだけの制度になり、モラルハザードにつながります。
そこで、INIADではChatGPTの利用について制限を付けないだけでなく、むしろ推奨することを考えています。
その理由は、ChatGPTを使うことが必ずしも「自分の頭で考えない」ことにつながるとは思わないからです
ChatGPTとは対話のセッションを何度も続けることができ、その過程で自分の考えを深めることもできます。そこが、聞いて答えるだけの検索エンジンとは大きく異なる点です。
実際、同じ課題をAIを使って解かせても、どう設問するか、回答に対して聞き返して深掘りするか、など使う人が適切な対話ができれば──そして、最後のまとめにあたり自己の判断で取捨選択し、必要なら補足や書き換えができるかまで、その人の能力により結果の質が大きく変わります。ChatGPTにレポート課題を投げて最初に出てきた回答をそのまま出す「撮って出し」では、回答はいかにもな凡庸な回答しか出ないのです。
逆に言うと、ChatGPTを使うことを許すのは、学生が「楽ができる」ようになるのではなく、その結果の質がより厳しく評価されるということなのです。単に「正しい」だけでは低い評価にしかならず「ユニークな視点がある」とか「深く検討している」など、より高度な結果を求められるようになります。そのためにINIADでは、より深い評価を行うための教育スタッフの負担を軽減できる評価のサポートAIのシステム開発も行っています。
「自分の頭で考える」ためのChatGPT
先に上げたように「自分の頭で考える」ために必要な姿勢の一つは「別の立場に立って、問題を見直す」というものです。最初のうちは、これを自分ひとりで行うのも難しいことも多いでしょう。しかし、ChatGPT──特にGPT-4ベースのChatGPTを「壁打ち」の相手にできれば、AIにアンチテーゼを考えてもらい、弁証法的な思考を繰り返し、より深く課題を考えるような思考の訓練も可能になります。
わからないことがあっても、何回でもいろいろなやり方で説明してもらっても恥ずかしくありません。また日本の学生は正面から反論されることを自己への攻撃と捉える傾向があり、ディベートで感情的になることもありますが、AI相手の「壁打ち」なら「自分自身の感情を管理する」のも容易でしょう。
このような対話を通して「自分の頭で考える」訓練は、哲学だけでなくINIADで教えるすべての学問分野で有用です。AIは、いやがりもせずずっと付き合ってくれる最高の「思考のためのバディ」になるのです。
さらに言えば、最終的な考査においては、ネットワークが使えない状況で試験を行います。ChatGPTを訓練相手として日頃から自らを高めることをせずに、楽をしてその回答を利用しているだけの学生は当然最終評価は低くなります。そして、その差はさらに大きくなることでしょう。
それは、まさに将棋の世界で藤井聡太さんがAIをバディとして精進し、その成果で本番を勝ち抜き六冠に至った道と同じなのです。
さらに、ChatGPTを使って思考を深めるスキルは、これからのINIADの学生が社会にでたときに強く求められる資質です。そのためINIADではChatGPTをどう使うかのプロンプトエンジニアリングについて、新しい教科として教育していく計画です。
また、ChatGPTでは課金しないと使えないGPT-4モデルを使えるかどうかについての不公平が生じるという懸念があります。そこでGPT-4モデルとプログラミング教育において使えるAPIを利用できるようにする環境整備を、INIADの全学生向けに行います。
なお、生成系AIの急激な進化という新しい状況に対応するということで、すべてはアジャイルであり、この方針も結果を見て変更するかもしれません。
一番の懸念は、対話により考えを深めるのでなく設問をそのままコピーし、出てきた最初の回答をそのまま提出するような「自分の頭で考えていない」使い方しかしない学生が出てくることです。これがあまりに目につくようなら、その学生の利用を停止するかもしれません。
しかしながら、ChatGPTの利用に制限を付けることは、学生がより深い思考をすることを阻害するだけでなく、現代社会における技術革新に対する抵抗感を育ててしまうことにもつながります。ぜひ、学生の皆さんが正しく「自分の頭で考えて」ChatGPTを使ってくれることを切に願っています。
繰り返しになりますが、学生がChatGPTを使って自分の考えを深め、より高度な思考力を身につけられるように、適切な環境・指導・教材の提供をINIADでは積極的に進めていきます。
ChatGPTを使って自分自身を疑い、新しいアイデアを生み出すことができる学生は、自己実現型人材として社会で活躍できるでしょう。INIADは、ChatGPTを使った思考の深め方を学生に教え、より高度な思考力を身につけられるよう支援していきます。これからの時代に必要とされる知識とスキルを身につけた、自己実現型の人材を育成していくことが、INIADの使命であり、責任でもあるのです。
坂村 健
